Data Management
OpenIO SDS offer a full set of data management features designed for the best efficiency and performance while maintaining a low $/GB, thanks to the ability to store and move data to the best-suited media for each single workload. A particular focus is on data lifecycle management and its automation, allowing users to ease application development and simplify storage management.
Storage Pools
Groups of storage media, hard disks, or SSDs can be configured to isolate specific types of traffic or objects from others. Data can be moved from one pool to another with simple operations or through automated tasks, enabling automated tiering. This improves multi-tenancy, performance consistency, and eases the organization of data across different media pools.
Automated Tiering
With storage tiering, it is possible to configure classes of hardware and select a specific one when storing data. This mechanism is called a storage policy. For example, a pool of high performance disks (like SSDs) can be configured in a special class to store objects that require low latency access. Several storage policies can be configured for the same namespace. They can be associated with specific hardware, but also with old or new objects, with a specific data protection mechanism for a particular dataset, and so on.
Dynamic Storage Policies
Storage policies are OpenIO’s way of managing storage tiering. They consist of triplets describing constraints set by the requestor:
- Which storage class is to be used (the kind of device and its fallback, i.e., fast SSD, SAS drive, tape, etc.);
- How data is to be protected (simple replication or sophisticated erasure encoding);
- Whether data is to be processed (compressed, encrypted, etc.).
All possible storage policies are namespace-wide, with default configurations that can be changed on the fly. These defaults can be overridden on a per-container basis.
Data protection is flexible, starting from a simple, multiple-copy mechanism, up to erasure coding, allowing users to choose the appropriate option for their needs, both in terms of protection and efficiency.
Dynamic data protection policies are also available. They allow the system to automatically select the best data protection mechanism after examining the characteristics of the stored object, associating optimal efficiency and data protection for each object stored in the system.
OpenIO has designed a dynamic data protection mechanism that automatically selects the best data protection mechanism according to the characteristics of the stored object, thus combining optimal efficiency and data protection. It is therefore possible to have several storage policies for each domain / user / bucket, then to assign rules to apply these policies, depending on the size of the object to be stored or other characteristics.
In a context where you do not know the type of file to store, the use of the dynamic data protection mechanism implemented by OpenIO is therefore recommended.
As an example, both x3 replication and 14+4 erasure coding can be assigned for a new bucket, with the rule that files smaller than 128KiB are replicated, while larger files use erasure coding.
As an illustration, for an 8 KB object, we obtain:
- 3 copies: a total capacity of 8 x 3 = 24KB but only 3 IOPS.
- EC 14 + 4 (considering a piece of 8KB): 8 x 18 = 72KB and 18 IOPS. In this case, a multiple data protection policy is not only better in terms of performance, but also in terms of capacity consumption.
For an 8 MB file, you get:
- 3 copies: a total capacity of 8 x 3 = 24 MB
- EC 14 + 4: the total capacity is approximately 10.2 MB In this case, no matter what the IOPS are, erasure coding saves a lot of storage space.
Data Compression
Applied to chunks of data, this reduces overall storage cost. Decompression is made in real time during chunk download, with an acceptable extra amount of latency and CPU usage. Compression is usually an asynchronous job to avoid hurting performance, and you can specify which data you want to compress (data age, mime-types, users, etc.).
Data Encryption
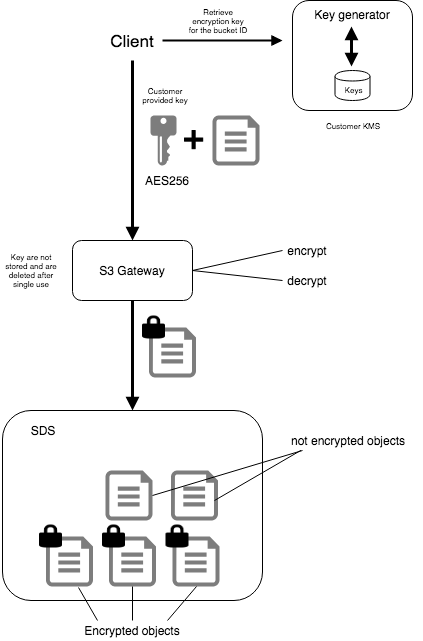
OpenIO supports Data at Rest Encryption with keys provided by customers in each request. Encryption is managed at the gateway level and is fully compatible with Amazon S3’s implementation of server-side encryption.
You manage the encryption keys and OpenIO manages the encryption, as it writes to disks, and decryption, when you access your objects.
Data directly accessed on disk thereby are unreadable, thus ensuring that data stays secure.
For more information, see Data at Rest Encryption
S3 Lifecycle compliance
OpenIO SDS supports S3 object life-cycle management, allowing users to set up time-based rules and trigger actions accordingly.
Automations can be set to move, compress, or delete data by age, last modified date, or other characteristics, improving system efficiency and data placement for optimal performance and capacity utilization.
No SPOF architecture
Every service used to serve data is redundant. From the top level of the directory to the chunk of data stored on disk, all information is duplicated. There is no SPOF (single point of failure): a node can be shut down, and it will not affect overall integrity or availability.
Replication and Erasure Coding
Configurable at each level of the architecture, directory replication secures namespace integrity. The service directory and metadata containers can be synchronously replicated to other nodes. Data can be protected and replicated in various manners, from simple replication that creates multiple copies of data to erasure coding, or even distributed erasure coding. This allows users to choose the best compromise between data availability and durability, storage efficiency, and cost.
Versioning
A container can keep several versions of an object. This is configured at the container level, at the time of its creation, for all its objects at once. It may be activated during the container’s life. If no value is specified, the namespace’s default value is used. When versioning is disabled, pushing a new version of an object overrides the former version, and deleting an object marks it for removal. When versioning is enabled, pushing an object creates a new version of the object, and previous versions of an object can be listed and restored. The semantics of object versioning has been designed to be compliant with both Amazon S3 and Swift APIs.
Container Snapshots
OpenIO SDS provides tools to make container snapshots. The new container is built by duplicating metadata and links to the original data chunks at the moment of the snapshot creation. Practically, you create a new container, starting from an existing one, which points to the same data chunks as the original container. Each operation performed on the new container does not affect original data but creates new objects or data chunks for their updated parts. Snapshots are synchronous operations, during which the container is in read-only mode.
Data Integrity Checks
Integrity checks are performed periodically to ensure that no silent data corruption or loss occurs.
Geo-Redundancy
OpenIO SDS allows storage policies and data to be distributed across multiple datacenters. Depending on distance and latency requirements, data storage clusters can be stretched over multiple locations synchronously or replicated to a different site asynchronously.